Bringing large volume of data – folders & files – from legacy drives, network shares, archives can be a daunting process. But is it something that every system administrator or a DAM/MAM manager has to deal with.
Below you will find a number of strategies customers have adopted to migrate data.
With any strategy Zoom gives you a number of ways to migrate files and apply metadata on incoming assets:
- Hot Folder for ingesting dropped assets, with a Zoom Metadata property file configured to apply same set of metadata values to a batch of dropped assets
- Hot Folder for ingesting dropped assets, with a Zoom CSV spreadsheet to apply unique metadata values per file. Requires creating a CSV file with required metadata per asset a-priori.
- Zoom Check-In metadata custom forms to capture metadata from a user manually prior to ingest via manual batching
- Using custom automation scripts extract metadata from file/folder name and bulk apply automatically while ingesting from a hot folder
- Using custom automation scripts extract metadata from XML files and apply automatically while ingesting from a hot folder
- Pull metadata from an external system or a database and using Zoom Metadata API to apply metadata post-ingest.
- Automatically apply embedded metadata in the XMP section inside file formats that support XMP such as PSD, AI, JPG, PNG etc.
- Using or Data Migration service which includes our Data Migration App for automated batching of large file set. Note this needs a statement of work (SoW).
As-Is Strategy
Bring in existing folders with files on legacy shares/drives as-is by dragging-n-dropping into Asset Browser or using Zoom Hot Folders. Zoom will index the file name & folder name for searching automatically.
Pros
- Simplicity: Not much thinking needed
- Get everything inside sub-folders via the recursive ingest function in Zoom
- Zoom can search file or folder name just as it searches metadata in other word folder names can behave as metadata with Zoom’s ability to perform partial string search on the folder name
Cons
- No batch management: Ingest will nor batch a large file data set into chunks like 1000 files at a time
- Slow, failure prone process: If a large batch doesn’t import, user needs to manually break it into smaller batch till it ingests
- No batch drive reporting or resumable batch migration
- No illegal character replacement
- No duplicate detection
- Garbage In, Garbage Out: Existing folder structure may be too inconsistent and chaotic to salvage
Scrub First Strategy
- Instead of bringing in assets as-is, create a staging area on a shared drive.
- Have users copy or move specific folders they want to bring forward to Zoom.
- Clean-up the folder/file names prior to ingest
- Delete garbage assets & folders
- Perform re-organization prior to ingest
Pros
- Reduce inconsistent folder structure by cleaning up first
- Reduce the migration set to a more manageable, smaller pool of folders & files
Cons
- House-cleaning can be time consuming when dealing with millions of assets
- Project files such as AEP, C4D, Maya, PrPro may break if linked assets are re-organized outside
Need-Basis Strategy
- Instead of bringing in assets prior to launch of the Zoom Asset Management system, start with an empty slate
- When the users need specific set of assets, they grab it from the existing shares/drives and ingest it just-in-time
Pros
- No need to define a migration plan!
- User driven migration allows the Zoom repository to be populated with only relevant files as opposed to everything
Cons
- Need to maintain multiple storage or repositories
- Users may not realize data is not migrated and could duplicate assets
- User adoption issues: If users do not find their existing folders & files they may not get comfortable with the new system
Mapping Strategy
– Instead of a manual scrub, if consistent rules can be defined to map an existing folder structure pattern to new folder structure pattern in Zoom, the process of mapping can be automated using a Zoom hot-folder custom pre-ingest script
Pros
- Ensure the new folder structure is populated with the schema the organization wishes to adhere to going forward
- Automate intake of existing folders into new folders on Zoom
- Can detect duplicates and create Zoom smart-copies on the fly while ingesting to reduce disk space used by clones of the same asset.
Cons
- Requires developing custom scripts
Hot-Folder Ingest Strategy
- Zoom supports multiple hot folders on one or several machines. Each hot folder can have a pre-defined metadata property file with a fixed set of property with values
- Users can drop the assets into the correct hot folder and have it apply different set of metadata to incoming assets
Pros
- Bulk ingest with varied set of metadata per hot folders to quickly apply the correct metadata to related assets
- End user does not need to worry about where the files are going in Zoom and what metadata needs to be applied
Cons
- Create and manage hot folders
- Mistakes: Users could place the assets in the wrong folder causing incorrect metadata to be applied to the assets in that hot folder
Automated Ingest Strategy
- Zoom supports number of APIs and ingest frameworks to allow assets to be automatically ingest with custom metadata applied during the ingest process.
- Hot folder pre-ingest script hook can be used to create a custom automation to change folder structure or fetch metadata from an external source or extract metadata from file/folder names prior to ingest. In addition it can also be used to weed out duplicates and create smart-copies on the fly from the master asset.
- Multiple versions of the same assets stored as individual files (for instance asset_v1.psd, asset_v2.psd..) could be coalesced into a single de-duplicated file in Zoom via a pre-ingest automated script
- Zoom Metadata API allow metadata to be changed after ingest using a custom script.
- Workflow Auto-task script can be invoked from the Asset Browser to apply metadata to a set of assets on-demand. The auto-task can for instance take the user selected assets post-ingest extract the Product SKU embedded and lookup a PLM system to pull in more metadata.
- Zoom Data Migration service can be purchased for automated batch ingest
Pros
- Maximum flexibility in automating the migration of assets
- Custom metadata can be applied from variety of sources such as external PLM systems, databases as well as foreign metadata property files such as custom XML files.
Cons
- Requires developing custom scripts
- Requires statement of works and additional costs
Evolphin Data Migration Service
We understand that your team members and stakeholders are busy and an efficient data migration process is highly desirable. In working with multiple clients we have found our Data Migration Service to address this need effectively.
We will keep your implementation team’s focus on deployment activities rather than any tangential product specific or technology issues by assigning a Zoom specialist to work with you during the data migration and deployment process. Evolphin will provide check-lists to document the data migration requirements, as well as automation scripts to allow you to quickly migrate from an existing digital asset repository to Evolphin Zoom.
By eliminating the time spent on skills ramp-up inherent in data migration, this process will significantly lower the time commitment of key stakeholders in your organization.
As part of purchasing this service, license to our batch Data Migration tool is also made available to the customer. It is illegal to use the data migration tool without this service.
Process Outline
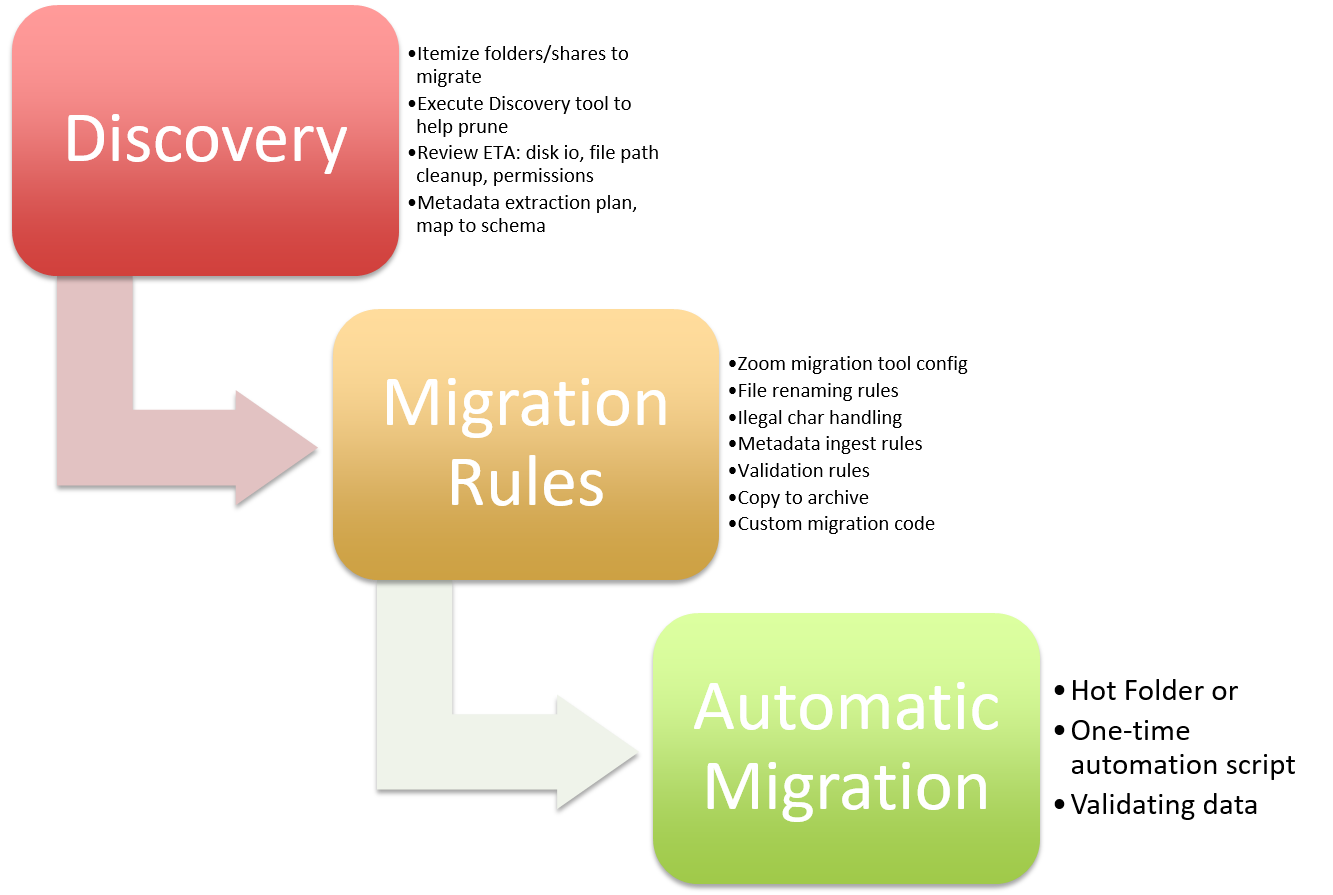
Review existing digital asset repository
While some organizations have an existing DAM/MAM (digital/medial asset management) system, most have a vanilla network share to store digital assets. Either way, we will work with all the key stakeholders to make sure we have the most up to date picture of the current repository via our data discovery app. The service includes determining the current repository structure, requires going back and forth with the stakeholders to validate the current and proposed folder structure, proposed changes to naming conventions, along with any requirements to prune unwanted files and duplicates. This process will include meetings (usually web-based) with the key stakeholders as well as internal work at Evolphin to create a data migration plan specific to the client. During this phase, it is very common to uncover aspects of the repository organization that could use some house-cleaning. Our goal is to use this opportunity to thoroughly understand the current repository structure and ensure the proposed structure in Zoom will meet current and future needs of the creative team.
- Key deliverable from client
- Current folder structure documenting the client/job folder schema
- Current repository size
- Predominant file types, average file sizes for each type
- Determine if project folders need to be reorganized
- Determine what files or file types need to be pruned before migrating to Zoom
- Determine if duplicates need to be eliminated, document duplicate detection insights
- Determine if multiple files need to be coalesced into a single file based on file naming conventions, for example foo_v1.psd, foo_v2.psd…foo_v20.psd can be delta compressed and coalesced into a single foo.psd file with 20 versions in Zoom
- Determine custom metadata if any that may need to be migrated
- Determine how much historical data needs to be migrated to Zoom – latest versions only, all versions or up to a cut-off date
- Key deliverable from Evolphin
- Analyze the client deliverables above to create a client specific migration plan in a statement of work
- Estimate time & effort involved in creating automated scripts or tools for data migration
Review the data migration plan
Once Evolphin has analyzed the data migration requirements, our team will work internally to prepare the most efficient plan to migrate to Zoom. The deliverable is a document that describes the migration plan, along with all the automation points. After reviewing this with the client, we will use the approved migration plan as the basis for the next step.
- Key deliverable from Evolphin: Statement of work outlining the proposed data migration to Zoom, with all the automation points defined; define new extensions, scripts/programs that need to be developed for automation
- Key deliverable from client: Review and approve the data migration plan with automation points spelled out; review and approve extensions or scripts that need to be developed
Write Automation scripts or programs
Based on the agreed upon automation scripts, extensions, Evolphin will create the scripts or work with the client to develop the needed scripts and/or extensions. These scripts will be downloaded on the legacy and/or Zoom server so that they are available as automated action for migrating data.
- Key deliverable from Evolphin and/or Client: Fully tested Automation scripts, extensions
- Integrate the automations with the Data Migration app based workflow
Revise the automated migration tools
After iterating through the automated data migration tool, the client might require further tweaks to the automation scripts. Though it is rare, sometimes it may be necessary to extend the functionality of the Zoom ingestion engine itself to meet additional requirements that were uncovered during the deployment. Evolphin will work with the client to ensure any last minute changes or glitches are addressed to get a seamless migration.
- Key deliverable from Evolphin: Statement of work for potential changes to automation scripts or in the extremely rare case enhancements to the Zoom data ingestion module
- Key deliverable from client: Review dry-run results and determine changes or extensions that may be needed to plug any gaps in the automated migration tools.
Using Evolphin Data Migration tool
Once the data migration service statement of work (SoW) is signed, Evolphin will make available and configure the tool. The tool
The Zoom Data Migration tool is configurable to a customer’s folder set and currently supports the following unique features compared to the normal ingest/check-in app:
- Automatic batch creation from the large file set in folders unlike the normal ingest or check-in app
- Illegal character in a file or folder name is replaced with a configurable legal character
- Extensive report generation in the client UI to report on errors, migration status, estimated completion time
- Uses a separate SQL database of tracking batches of assets
- Pause/Resume feature that allows media managers to restart migration from where it left off by tracking batch states in a SQL database
- Duplicate detection algorithms: If a duplicate is detected, create a smart link in Zoom pointing to the original source file as well as symbolic links on the PSAN storage
In addition, similar to the check-in app the tool also support these features:
- Ignore file with some specified extension or pattern or file types
- Create direct Ingest or a proxy based on file size (configurable) and file type (configurable) rules
- Legacy file path is captured as metadata
- Any metadata present (as an XMP section) inside the file will be extracted and inserted into the Zoom database. Using the migration check-in dialog batch custom metadata can be applied for each top-level source folder.
- A limited set of metadata which can be expressed in Evolphin specified CSV format can be applied during ingestion.
- Certain technical metadata like file size, type, date etc is automatically extracted
- Indexing file or folder name for searching
Perform the actual data migration
Once the tools are ready, we will work with the IT representative to either train them to use the tools themselves or have our professional migration service team perform remote logins at scheduled time periods to perform the data migration as well as monitor the system for any issues during and post migration.
- Key deliverable from Evolphin: Automated tools & scripts for data migration, if engaged Evolphin professional service to perform remote login to do the data migration
At the end of the implementation cycle a report will be published which will contain recommendations and best practices required for smooth running of the Zoom repository as well as suggested next steps.