

Metadata is the lifeblood of an effective Media Asset Management (MAM) solution. Media managers rely on metadata to index, search for, and locate relevant assets—without it, users are left to sift through hundreds or thousands of terabytes worth of files to get the data they need.
But as those of you with the above-mentioned thousands of terabytes of data will undoubtedly know, this amount of data and the need to curate and tag it presents a paradox. As companies create more data, specifically during post-production, it becomes increasingly time-consuming and tedious to correctly tag all of it. The process of tagging data for efficiency purposes often ends up being incredibly inefficient.
This is where Artificial Intelligence (AI) and machine learning come in. While most solutions are not as precise as one might hope, AI and machine learning can perform initial metadata extraction and tagging, and the services are being constantly improved. For example, Google Video Intelligence API can analyze a video clip or image and apply up to 20,000 labels to it. That sounds like a lot, but to put it in context, some of the keyword dictionaries in use at companies today extend to over 100,000 labels—but this requires a human to edit and apply them. Since more labels are constantly being introduced to the AI algorithm as it learns, services like Google’s will only get better with time.
In addition, AI algorithms don’t always tag things correctly, but most of the time they do an adequate job. As a result, machine learning for MAM should be viewed as an aid for media managers, automatically analyzing media and applying pre-existing tags, and used in tandem with a human who is refining the metadata for select assets and adding longer phrases. In situations where a company does not have the time or staff necessary to tag legacy assets, it can be useful for making those legacy assets discoverable without requiring hours of human labor.
Because machine learning and AI services are constantly improving, one day they will return results equivalent to, or even better than, a human metadata tagger. However, that time is in the future, so for now it is important that the metadata created by AI services be labeled separately from the metadata created by people. It is important that a MAM system that integrates with machine learning services treat it as an aid and not a replacement for human work.
How Evolphin uses machine learning
Evolphin uses machine learning for two main purposes: discover on ingest, and analyze on demand.
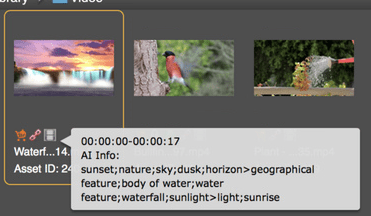
Discover on ingest
The Evolphin VideoFX module has an ingest server that can be customized to copy a video proxy or an image to a machine learning service like Google Video intelligence or Amazon Rekogniton API using their respective cloud storage. These APIs take this copy, run an analysis, and return metadata in a machine-readable format such as JSON.
Once the data has been returned, the Evolphin MAM then uses its API to set metadata tags in a custom metadata group to distinguish it from human curated groups. Provided the machine learning system can perform shot detection to distinguish scene changes in a video, Evolphin can set the returned tags on specific time codes and sub-clips within a video.
This analysis also integrates with Evolphin data migration tools, enabling users to automatically sift through millions of assets.
Analyze on demand
Using the Evolphin Zoom Asset Browser, a user can right click on any file and and automatically send a proxy of the asset to one of the aforementioned machine learning services. As with all Evolphin integrations, the process runs in the background while you continue to work. Once Evolphin receives the returned data, it can automatically tag it into preconfigured metadata fields for easy discoverability.
To learn more about how Evolphin is using machine learning to transform media asset management, contact us today.